Machine Learning für Analysen von Umweltdaten nutzbar machen
Wie lassen sich heterogene Datenbestände in Umweltbehörden für intelligente Datenanalysen mit KI-/Machine Learning-Methoden erschließen? Das wird im neuen Forschungsprojekt Simplex4Learning untersucht.

Umweltbehörden verfügen über umfangreiche Daten zu Themen wie Luft- und Wasserqualität oder den Zustand von Wäldern. Diese Daten sind unterschiedlich strukturiert, weil sie aus heterogenen Quellen, wie beispielsweise von Messstationen, Drohnen oder Satelliten stammen. Bei Forschungen zur Zustandsbewertung von Bäumen hingegen, wo Proben aufwendige Laboranalysen nach sich ziehen, liegen weniger Daten vor. Um ökologische Phänomene und ihr komplexes Zusammenspiel möglichst gut verstehen und überwachen zu können, sind KI-Methoden wie Machine Learning (ML) nicht nur dafür geeignet, wachsende Datenbestände mit intelligenten Datenanalysen auszuwerten, sondern auch fehlende Daten mit geeigneten Vervollständigungsmethoden zu ergänzen. Solche Analyseansätze erfordern jedoch vertiefte ML-Kenntnisse, die in Umweltbehörden standardmäßig nicht verfügbar sind.
Forschungsprojekt fördert Anwendung von ML-Methoden in Umweltbehörden
Mit dem Ziel, die praktische Anwendung von ML-Methoden in der Breite zu fördern, ist das Forschungsprojekt „Intelligente Umweltdatenanalyse durch automatisiertes maschinelles Lernen für Fachanwender“ (Simplex4Learning) im Oktober 2023 gestartet. Das auf 30 Monate ausgelegte Projekt wird vom Bundesministerium für Bildung und Forschung (BMBF) im Rahmen der Fördermaßnahme „KMU-Innovationsoffensive IKT" unterstützt. Neben Disy, dem Koordinator des Forschungsprojekts, zählen zum Projektkonsortium Simplex4Data (S4D), ein Unternehmen mit langjähriger Erfahrung in der Harmonisierung und Bereitstellung von Umweltdaten, sowie Hochschule für Technik und Wirtschaft Berlin (HTW).
Damit im Forschungsprojekt das maschinelle Lernen mit realen Umweltdaten erfolgen kann, sind als assoziierte Partner das Landesamt für Natur-, Umwelt- und Verbraucherschutz Nordrhein-Westfalen (LANUV), die Landesanstalt für Umwelt Baden-Württemberg (LUBW) und der Landesbetrieb Forst Brandenburg (LFB) eng eingebunden. Sie haben großen praktischen Bedarf an den zu entwickelnden Lösungen und können mit konkreten Beispieldaten und Anwendungsfällen aus den drei Bundesländern das Vorhaben ganz praxisnah unterstützen.

Projektkonsortium Simplex4Learning
Der Simplex-Ansatz: Neue Methode für Datenbereitstellung

Datenmanagement-Tool Simplex4Data Bildrechte: Simplex4Data GmbH
Um heterogene Umweltdaten für das maschinelle Lernen effizient bereitstellen zu können, kommt der Datenhaltung eine Schüsselrolle zu. Der von Simplex4Data entwickelte Simplex-Ansatz ermöglicht die Datenhaltung als Daten-Pool. Kern dieses Ansatzes ist ein datenbankbasiertes Datenmanagement, das alle eingehenden Informationen (Simplex Import) themenübergreifend und einheitlich strukturiert verarbeitet (Simplex Reality), flexibel verwaltet (Simplex Scenario) und über standardisierte Dienste wieder bereitstellt (Simplex Service).
Das eröffnet neue Analyseperspektiven, da die Daten in einer einheitlichen, nicht zweckgebundenen Struktur bereitstehen. Deshalb soll im Projekt die Simplex4Data-Methode zur Datenbereitstellung für ML weiterentwickelt und für den Umgang mit großen Zeitreihen von Messdaten implementiert werden.
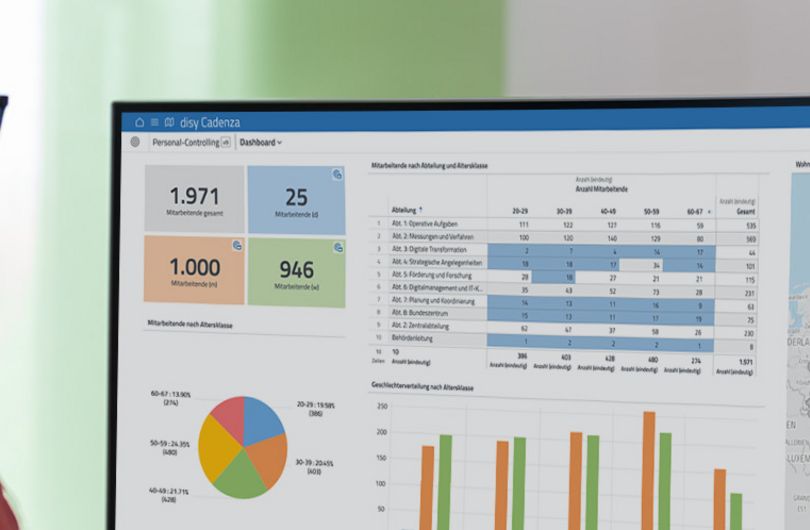
Maschinelles Lernen im Zusammenspiel mit disy Cadenza
Durch die Anschlussfähigkeit des Simplex-Ansatzes lässt sich dieser Daten-Pool mit einheitlich strukturierten Umweltdaten effizient in vorhandene (Geodaten-)Infrastrukturen integrieren. Damit kann die Datenanalyse-Software disy Cadenza bei allen Analyse- und Reporting-Prozessen darauf zurückgreifen. Mit der neuen Analyse-Erweiterung, die seit Release 9.3 als Beta-Version verfügbar ist, können darüber hinaus intelligente Analyseverfahren, die mit Methoden des maschinellen Lernens arbeiten, auch diesen zusätzlichen Daten-Pool nutzen.
Die Idee ist nun, dass Anwendende aus disy Cadenza heraus Daten, Lern- und Analyseaufgaben an die Analyse-Erweiterung senden, die Zugriff auf zuvor trainierte KI-Modelle hat, die in einem ML-Repository liegen. Um diese gezielt erstellen (trainieren) zu können, wird im Rahmen des Projekts ein ML-Framework aufgebaut, welches die automatische Erstellung von ML-Modellen mit unterschiedlichen Algorithmen (AutoML) unterstützt. Die ML-Resultate und generierten Erklärungen werden über die Analyse-Erweiterung wieder an disy Cadenza übermittelt und können dort von den Anwendenden visualisiert oder für darauf aufbauende Datenanalysen weiterverarbeitet werden. Ebenso wie AutoML lassen sich weitere KI-Komponenten zur effizienten und robusten Entwicklung und Anwendung der ML-Modelle (MLOps) oder zur Erklärbarkeit (Explainable-AI) anbinden.

Konzeption Simplex4Learning
Durch diesen konzeptionellen Ansatz können Anwender:innen zukünftig aus disy Cadenza heraus KI-Modelle verwenden, ohne dafür selbst vertiefte Kenntnisse zur Anwendung von KI-Algorithmen haben zu müssen. Sie filtern beispielsweise ihre Daten zu den Themen Baumsterben und Niederschlagsverteilung und schieben alle Klimadaten mit der Prämisse „Temperaturtrends“ an die Analyseerweiterung. Wenn die KI schon vergleichbare Anwendungsbespiele verarbeitet hat, wird ein Trend übermittelt, der vom Anwendenden auf fachliche Richtigkeit zu überprüfen ist. So kommen ML-Methoden in der Breite in die praktische Anwendung und können durch die Identifizierung von Zusammenhängen, zum Beispiel bei der Ursachen-Wirkung-Forschung im Waldökosystem, ihren Nutzen entfalten.
Ausblick auf die Projektergebnisse von Simplex4Learning
Beginnend mit einfachen technologischen Fragestellungen auf Basis der Umweltdaten von LFB und LANUV wird sich das Projektkonsortium schrittweise komplexeren Problemen und übertragbaren Lösungen annähern, die dann mit den Daten der LUBW überprüft werden. „An das Forschungsprojekt Simplex4Learning knüpfen wir große Erwartungen, insbesondere für die konkreten Fragestellungen unserer Kunden. Es dient auch unserer Vision, das Potenzial von vorhandenen Daten bestmöglich zu erschließen“, so Dr. Andreas Abecker, Leiter Forschung und Innovation bei Disy. „Viele Kunden können mangels praktikabler Werkzeuge nur mit großem Aufwand sowie viel mathematischem und softwaretechnischem Hintergrundwissen die neuesten Verfahren zur vertieften Analyse ihrer Daten nutzen. Hier wollen wir neue Ansätze bieten“, gibt Dr. Abecker einen Ausblick auf die zu erwartenden Forschungsergebnisse.