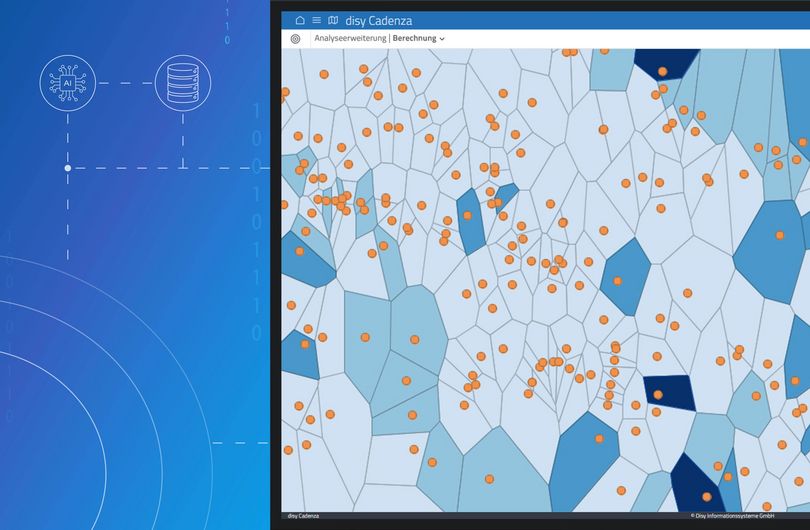
Analyseerweiterungen in disy Cadenza: Anwendungsbeispiele von einfachen Skripten bis KI-Verfahren
Analyseerweiterungen erweitern disy Cadenza um flexible Analysemethoden und Visualisierungen. Von einfachen Skripten über statistische Methoden bis hin zu KI-Verfahren – eigene Analysen lassen sich nahtlos integrieren und zentral bereitstellen. Wir zeigen praktische Beispiele und spannende Use Cases.
disy Cadenza lässt sich mithilfe von Analyseerweiterungen um zusätzliche Analyseverfahren und Visualisierungen erweitern. Sie können beispielsweise mit Python oder R entwickelt und dann über die API eingebunden werden. Dadurch entstehen neue Möglichkeiten für die Auswertung und Fachteams können ihre Verfahren zentral bereitstellen, während disy Cadenza die Data Governance sichert.
Neben denen durch disy Cadenza bereitgestellten klassischen BI- und Geo-Analytics-Funktionen ermöglichen solche Erweiterungen auch fortgeschrittene statistische Methoden, Data Mining sowie KI- und Machine Learning-Ansätze. Die Einbindung in disy Cadenza erfolgt über eine REST-Schnittstelle. Bei der Entwicklung unterstützen gängige Tools und Bibliotheken. So profitieren alle Nutzenden von erweiterten Analysefunktionen – ohne spezielles Fachwissen.
In diesem Beitrag werfen wir einen Blick auf verschiedene Use Cases anhand von konkreten Beispielen. Das Anwendungsspektrum ist riesig. Grundlegende Informationen zu den Analyseerweiterungen in disy Cadenza finden Sie in diesem Beitrag.
Mögliche Anwendungsfälle: Von wissenschaftlichen Diagrammen über Datenanreicherungen bis zu Vorhersagen und Simulationsmodellen
Die Analyseerweiterung bietet viele neue Möglichkeiten in der Datenanalyse. Hier ein paar Beispiele:
Visualisierung
Zusätzlich zu den bewährten Standardfunktionen von disy Cadenza ermöglichen ergänzende wissenschaftliche und KI‑basierte Visualisierungen noch mehr Datenanalyse-Möglichkeiten innerhalb von Dashboards in disy Cadenza.
Datenanreicherung
Aufbauend auf bestehenden Datensätzen ermöglicht die gezielte Datenanreicherung um zusätzliche Spalten oder Zeilen eine vertiefte Analyse – etwa durch statistische Verfahren wie Clusterbildung, die Einbindung externer Services mit aktuellen Informationen oder den unterstützenden Einsatz von KI‑Technologien wie LLMs zur Auswertung großer Textmengen.
Vorhersagen
Der gezielte Einsatz statistischer Modelle und KI‑gestützter Verfahren ermöglicht fundierte Prognosen auf Basis vorhandener Daten.
Simulationsmodelle
Die Berechnung neuer, unabhängiger Datensätze auf Basis vorhandener Daten eröffnet zusätzliche Analyse‑ und Nutzungsmöglichkeiten.
Fortschrittliche Analysen: Muster erkennen, Chancen nutzen
Weiterführende Analyseverfahren eröffnen eine ganzheitliche Perspektive auf die Daten und machen so verborgene Zusammenhänge und Potenziale sichtbar. Diese Erkenntnisse ermöglichen neben einer präziseren strategischen Ausrichtung auch die Identifikation neuer Chancen. So werden Daten zu wertvollen Entscheidungsgrundlagen. Im Folgenden ist eine Übersicht über mögliche fortschrittliche Analyseverfahren zu sehen:
Segmentierung / Clusterung
Gruppierung von Elementen auf der Grundlage von Ähnlichkeiten
Prognose
Vorhersage der Zukunft auf Basis des bisher Beobachteten
Zeitreihenanalyse
Zerlegung von Zeitreihen in Komponenten wie Trends, Saisonalität, Zyklus und Rest
Klassifizierung
Gruppierung von Elementen anhand von definierten Merkmalen
Korrelation
Identifizierung von Beziehungen zwischen den Eigenschaften von Elementen
Sprachverarbeitung
Verstehen, Verarbeiten und Generieren natürlicher Sprache
Assoziation
Ermittlung der Häufigkeit des gemeinsamen Auftretens und Ableitung von Regeln wie "C folgt in der Regel auf A und B".
Anomalieerkennung
Erkennung von außergewöhnlichen, nicht zu erwartenden Ereignissen
Bilderkennung
(Wieder-) Erkennung von Strukturen in Grafiken wie z. B. Satellitenaufnahmen
Use Cases und Beispiele: Das kann man mit disy Cadenza und den Analyseerweiterungen aus den Daten rausholen
Wie mächtig unsere Analyseerweiterung ist, wie gut die Nutzerführung ist und wie vielfältig die Anwendungsmöglichkeiten sind, wird besonders klar, wenn man einen Blick auf konkrete Use Cases und Beispiele wirft.
Zusammengehörende Elemente mittels Clustering gruppieren
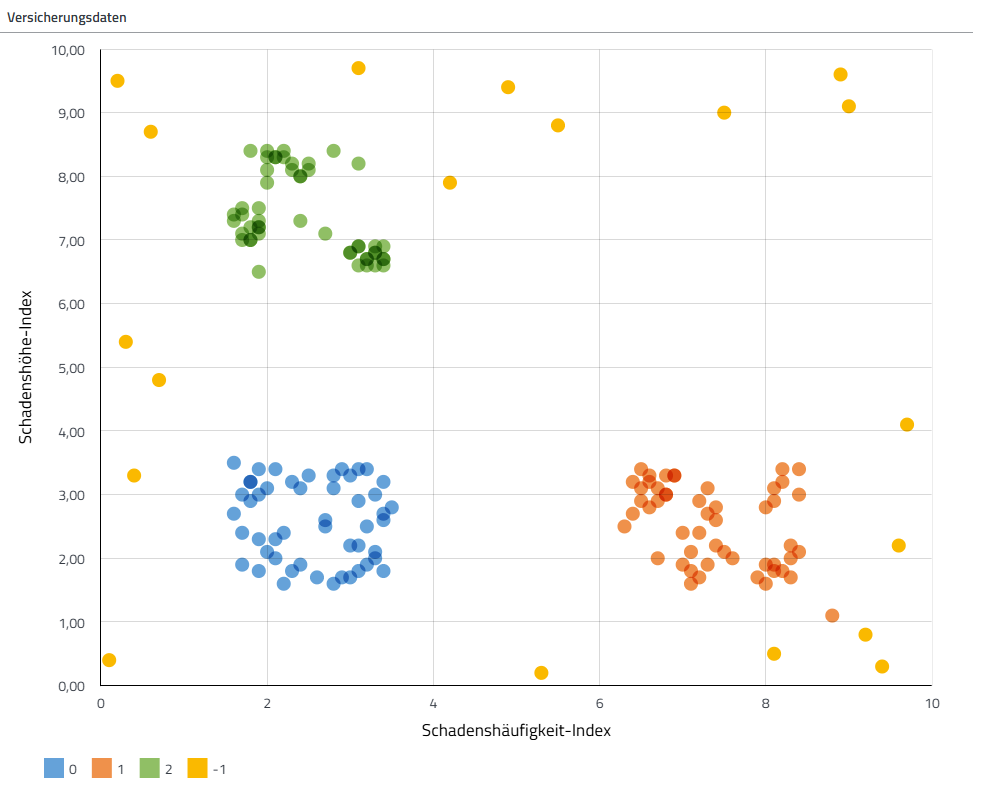
Clustering in disy Cadenza
Beispiel eins der Analyseerweiterungen ist der Clustering-Algorithmus. disy Cadenza übernimmt die Darstellung der Ergebnisse, hier am Beispiel von Versicherungsdaten.
Beim Clustering werden Elemente aufgrund von Ähnlichkeiten gruppiert und somit Zusammenhänge identifiziert. Dabei gibt es verschiedene Verfahren, wie bspw. DBSCAN, was auch in diesem Beispiel verwendet wurde. Die Versicherungsdaten sollen nach Schadenshäufigkeit und Schadenshöhe geclustert werden. Die Cluster werden automatisch erkannt und dementsprechend eingefärbt. Das Ergebnis sind in diesem Fall drei verschiedene Cluster und ein Ausreißer-Cluster:
- Cluster 0 (blau): Hierbei handelt es sich um wenige geringe bis moderate Schäden, also ein ausgewogenes Risikoprofil.
- Cluster 1 (orange): Die Kund:innen, die in dieses Cluster fallen, weisen viele kleinere Schäden vor.
- Cluster 2 (grün): Das grüne Cluster beinhaltet Kund:innen mit wenigen, aber teuren Schäden.
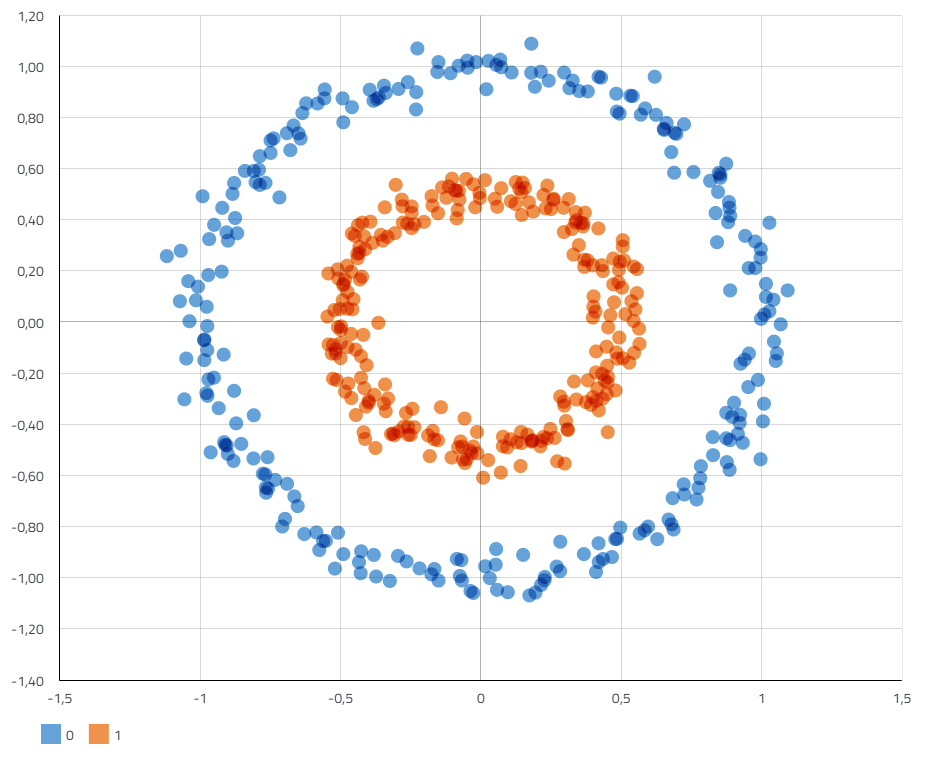
Weiteres Clustering-Beispiel
- Ausreißer (gelb): Hierunter fallen alle Kund:innen, die in keines der anderen drei Cluster fallen. Es handelt sich meist um extreme Kombinationen, wie viele hohe Schäden.
Cluster können aber auch so wie in der rechten Abbildung aussehen. Hier wurden zwei kreisförmige Cluster identifiziert und automatisch in verschiedenen Farben eingefärbt. Cluster können also verschiedene Formen haben.
Regression lässt Zusammenhänge erkennen
Eine Regressionsanalyse ist ein statistisches Verfahren, mit dem man untersucht, wie stark ein oder mehrere Faktoren (Variablen) Einfluss auf eine andere Größe haben. Man nutzt sie, um Zusammenhänge zu erkennen, Vorhersagen zu treffen und die Wichtigkeit einzelner Faktoren zu bewerten.
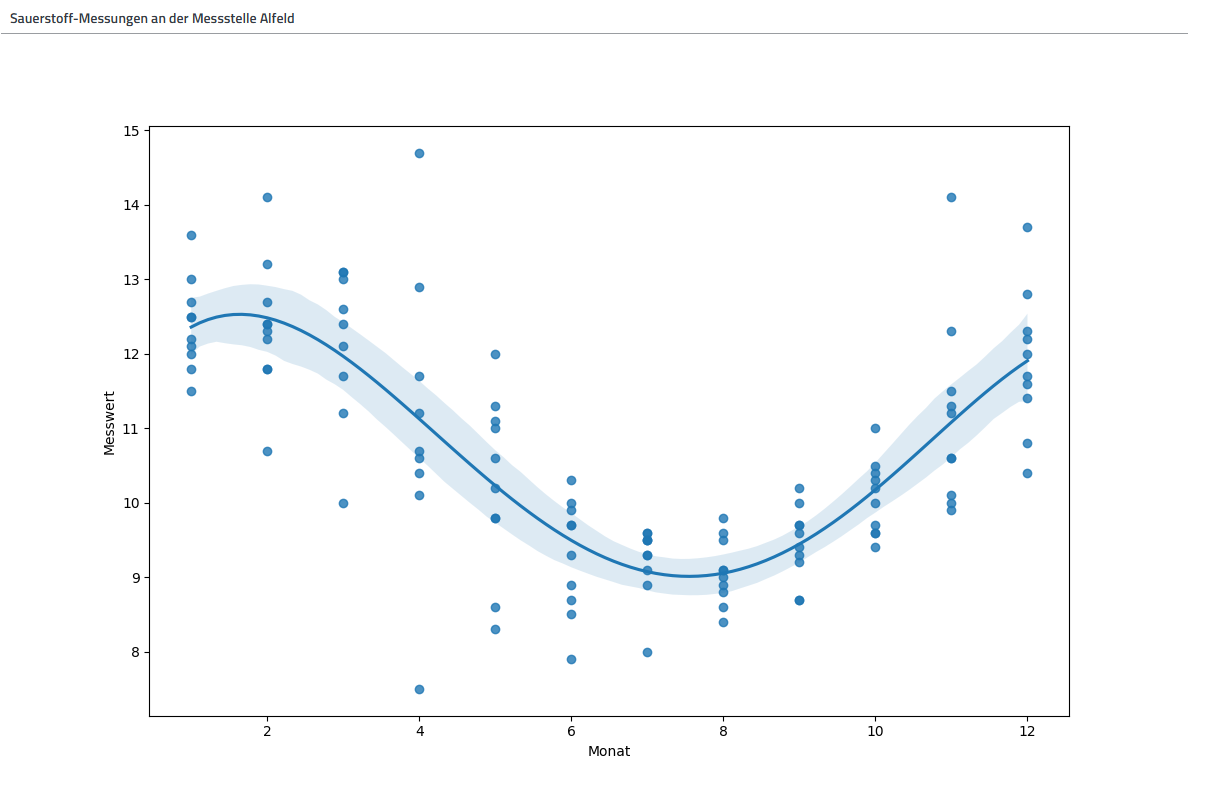
Regressionsanalyse
Wenn man z. B. den Zusammenhang zwischen Werbeausgaben (unabhängige Variable) und dem daraus resultierenden Umsatz (abhängige Variable) untersuchen möchte, würde die Regressionsanalyse ein Modell erstellen, das beschreibt, wie stark die Werbeausgaben den Umsatz beeinflussen. Das würde dann ermöglichen, den erwarteten Umsatz bei einem bestimmten Budget vorherzusagen.
Das Anwendungsfeld ist riesig. Im folgenden konkreten Fall werden beispielsweise Gewässerdaten untersucht. Es handelt sich um eine Polynomiale Regression. Analysiert wird der Sauerstoffgehalt einer Gewässermessstelle über die Monate. Auf Basis von Mustern in den bisher vorhandenen Messwert-Daten über die Monate, können Vorhersagen für die Zukunft getroffen werden. So ist es möglich, nötige Maßnahmen einzuleiten, bevor sie akut werden.
Keine Grenzen mehr bei der Datenvisualisierung
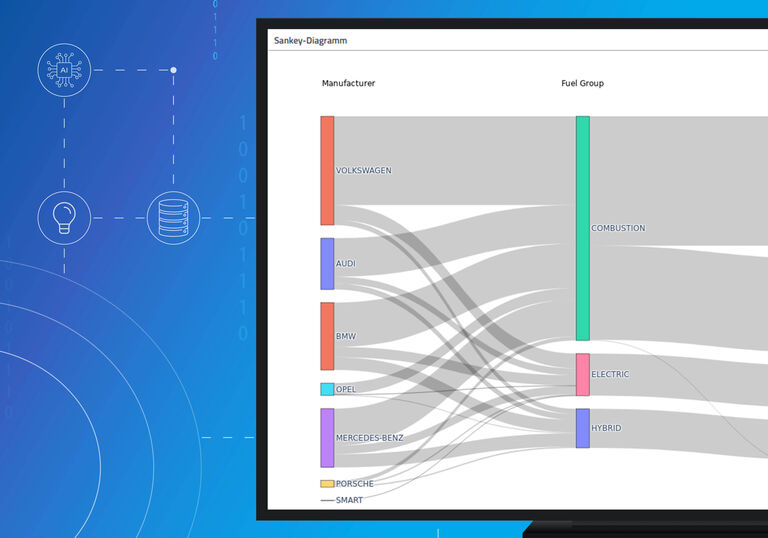
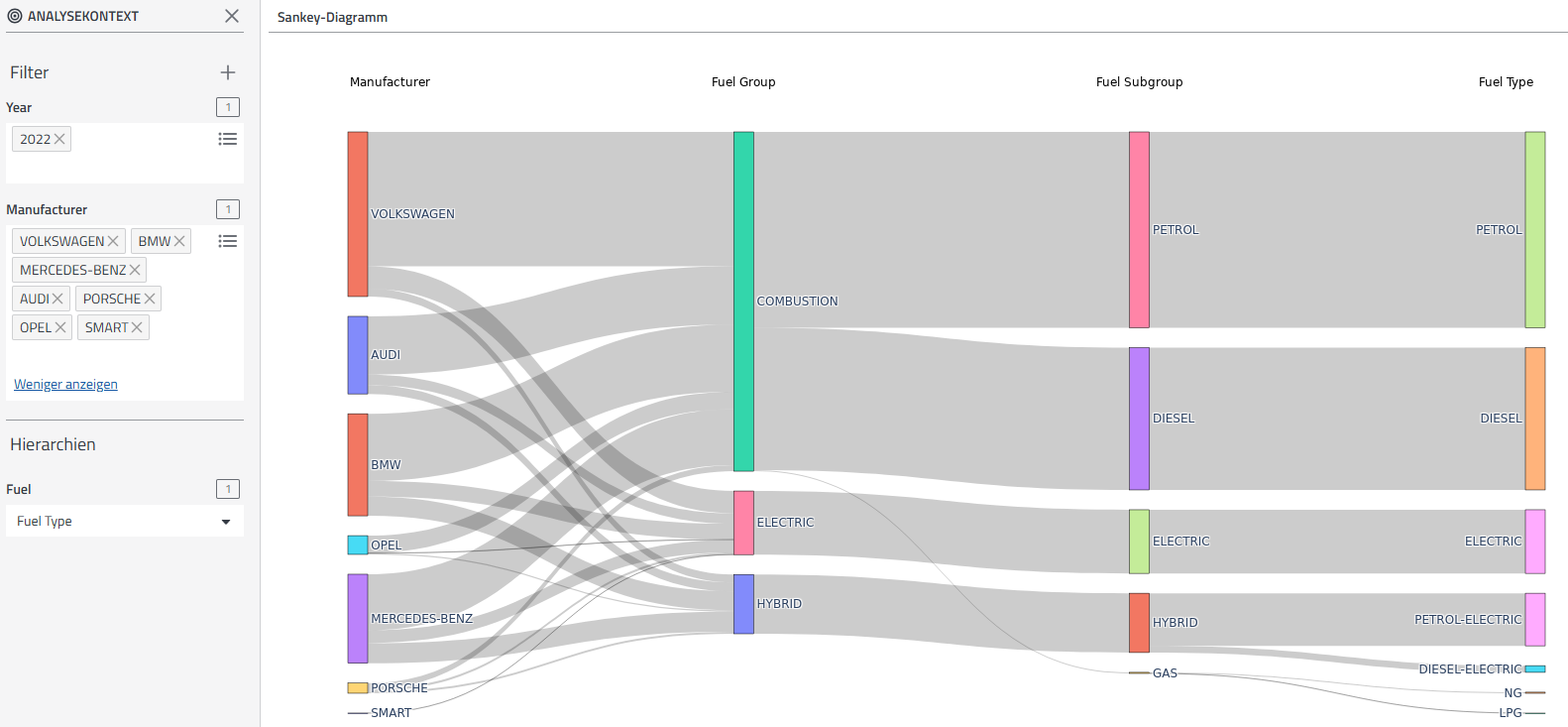
Mit den Analyseerweiterungen können Daten auf jede erdenkliche Art und Weise visualisiert werden. So auch im Diagramm in unserem Beispiel. Dabei handelt es sich nicht um ein statisches Bild. Das Diagramm ist interaktiv und reagiert auf Filterungen. Diese Visualisierungsart nennt man Sankey-Diagramm. Verbindungen und Zusammensetzungen werden dadurch sehr gut deutlich. Wie spielen verschiedene Komponenten zusammen? Woher kommen die Zusammensetzungen? Genau solche Fragen können damit leicht beantwortet werden.
Das Sankey-Diagramm gibt einen Einblick in die Fahrzeugneuzulassungen der deutschen Automobilhersteller im Jahr 2022. In diesem simplen Beispiel lässt sich übersichtlich visualisieren, welche Antriebsart diese vorweisen können. Es ist zu sehen: Die Neuzulassungen weisen einen sehr hohen Anteil an Verbrennerfahrzeugen auf. Außerdem stellte Volkswagen insgesamt mehr Fahrzeuge her als andere deutsche Hersteller, wobei der Großteil weiterhin auf Verbrennungsmotoren entfällt. Spannend: Im Jahr 2022 stellte VW mehr rein elektrisch betriebene als hybridbetriebene Autos her. Gemeinsam macht deren Anteil ca. ein Fünftel der Gesamtneuzulassungen VWs aus. Insgesamt machen (Teil-) Elektrische Fahrzeuge bei allen deutschen Herstellern einen beachtlichen Anteil aus, sind aber noch weit von der Menge an Verbrennerfahrzeugen entfernt. Alle diese Infos bekommt man nur durch kurzes Betrachten des Sankey-Diagramms.
Sankey-Diagramm
KI meets disy Cadenza
Kategorisieren und zusammenfassen im Ideenportal
Vieles, das früher mühsam von Hand gemacht werden musste, kann heute eine KI erledigen. Warum sollte man diese Vorteile in der Datenanalyse also nicht nutzen? In diesem Beispiel wurde KI für ein öffentliches Ideenportal genutzt. Bürger:innen haben hier die Möglichkeit, Verbesserungsvorschläge und Ideen für diverse Belange der Stadt, wie bspw. Sauberkeit öffentlicher Orte, in einem Online-Portal einzureichen. Die Informationsmenge, die daraus resultiert, ist immens. Deshalb nutzen wir die Analyseerweiterung, um Informationen zu strukturieren und zusammenzufassen. In je einem Dialog in disy Cadenza, der je nach Analyseerweiterung anders aussehen kann, werden zuerst
- alle Ideen so kategorisiert, dass sie inhaltlich zusammenpassen und danach
- eine Zusammenfassung pro Kategorie generiert.
Die Zeit, die man so durch das Vermeiden enormer Organisationsaufwände spart, kann direkt in die Umsetzung von Maßnahmen gesteckt werden.
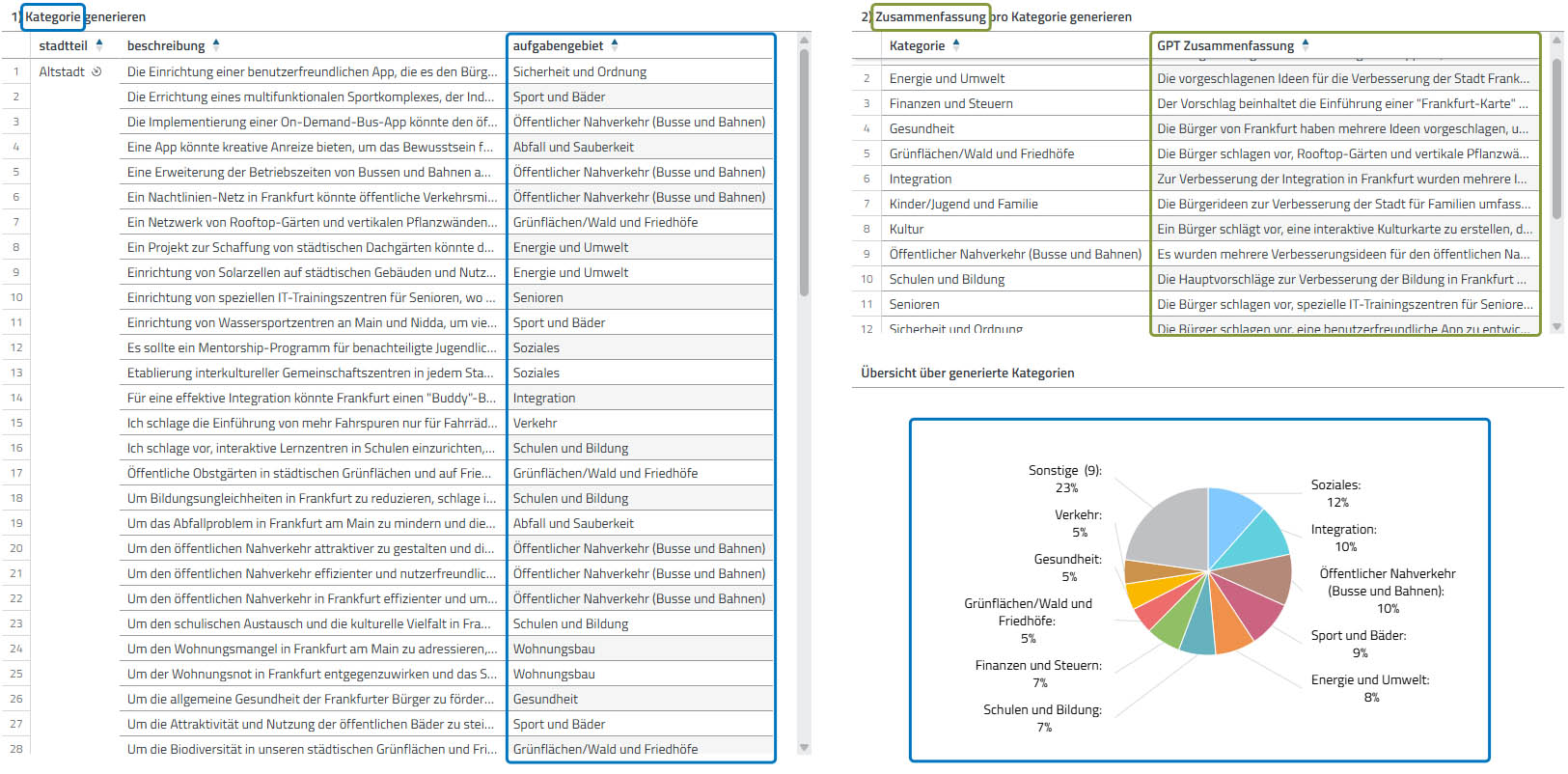
Daten kategorisieren und zusammenfassen
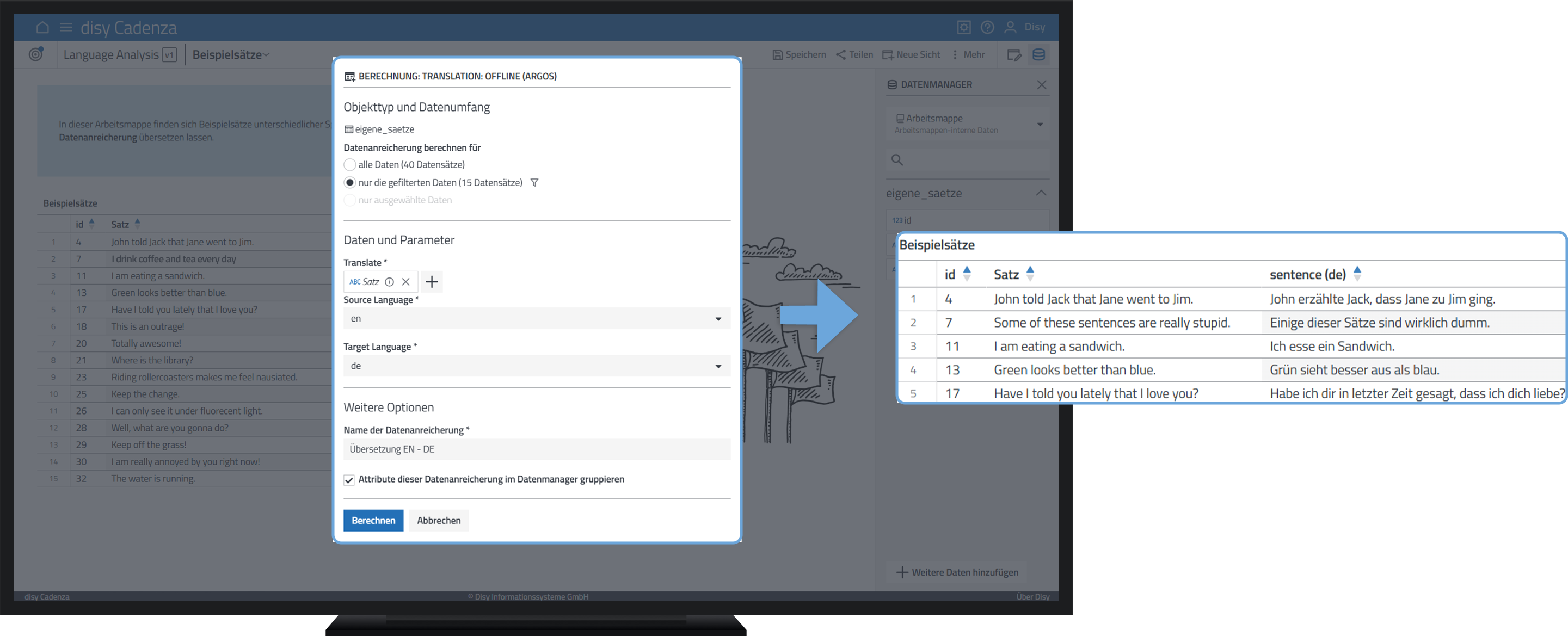
Inhalte automatisiert übersetzen
Übersetzung leicht gemacht
Daten leicht und automatisiert übersetzen? Large Language Models (LLM) machen es möglich. In diesem simpel gehaltenen Beispiel haben wir verschiedene Sätze auf Englisch vorbereitet. Mit der Analyseerweiterung, basierend auf einem LLM, können mit wenigen Klicks alle Sätze auf einmal im Nullkommanichts übersetzt werden. Natürlich kommt die KI hier nicht bei ein paar Sätzchen an ihre Grenzen. Auch große Datenmengen werden in kürzester Zeit übersetzt! Man könnte das Ganze also auch genauso mit hunderten von Sätzen machen – und in allen möglichen Sprachen.
Genug von den Beispielen? Dann werden Sie doch selbst aktiv und probieren Sie es einfach mal aus. Wir geben Ihnen unsere Tutorials für Analyseerweiterungen in disy Cadenza an die Hand. Damit können Sie direkt selbstständig loslegen.