Machine Learning soll visuelle Analysen mit disy Cadenza erleichtern
Zusammen mit dem FZI untersucht Disy im BMBF-Forschungsprojekt AIDA-Vis, wie sich maschinelles Lernen in disy Cadenza nutzen lässt, um durch Datenvisualisierungen (Visual Analytics) leichter Trends und Muster bei Datenanalysen erkennen zu können.

disy Cadenza bietet immer mehr Möglichkeiten, komplizierte Datenlagen zu analysieren und übersichtlich darzustellen. Dieser integrative Ansatz, der die benutzergetriebene algorithmische Datenauswertung mit visueller Analyse für die menschliche Interaktion kombiniert, wird auch als Visual Analytics bezeichnet und soll möglichst benutzungsfreundlich sein. Bereits das Erstellen einer vermeintlich einfachen Datenvisualisierung kann zeitraubend sein und mehr oder weniger gut gelingen. Um hier zu unterstützen, bietet disy Cadenza seit Kurzem eine einfache Generierung von Visualisierungsvorschlägen auf Basis von Heuristiken. Um diesen Ansatz auszubauen, untersuchen Disy und das Forschungszentrum Informatik Karlsruhe (FZI), wie sich mit den Methoden des Maschinellen Lernens und möglichst wenig Nutzerinteraktion immer bessere Visualisierungsvorschläge für konkrete Fragestellungen empfehlen lassen.
disy Cadenza bietet Visualisierungsvielfalt bei Datenanalysen
Darstellungen komplexer Sachverhalte in Form von Geschäftsgrafiken, Infografiken oder interaktiven Datenvisualisierungen erleichtern nicht nur das Erkennen von Zusammenhängen, sondern auch die Darstellung von Analyseergebnissen und ihre Kommunikation an Dritte. Die vielfältigen Möglichkeiten zur Visualisierung, die disy Cadenza schon immer bot, wurden in den vergangenen Jahren verstärkt ausgebaut, beispielsweise um die Darstellung von Phänomenen wie Hotspots und Bewegungsdaten oder die Analyse räumlich-zeitlicher Zusammenhänge. Durch individuell konfigurierbare Dashboards sowie kollaborative Bearbeitung von Arbeitsmappen in einer Gruppe von Kolleginnen und Kollegen ergeben sich mächtige Funktionalitäten, um auch komplexe Fragestellungen zu beantworten, ohne dass man vertiefte Kenntnisse in Data-Science-Technologien besitzen müsste. Damit wurde die Tür erstmals strategisch aufgestoßen, um disy Cadenza von einer Business-Intelligence- und Location-Intelligence-Plattform zu einer Augmented-Analytics-Plattform auszubauen, was als nächster Meilenstein der intelligenten Datenanalyse gehandelt wird.

Abb. 1: Beispiele für Datenvisualisierungen mit disy Cadenza
disy Cadenza bietet automatisierte Visualisierungsvorschläge
Ist eine Datenvisualisierung gelungen, dann kommt man häufig gar nicht auf den Gedanken, dass es auch alternative Darstellungen gegeben hätte. Tatsächlich sind aber zumeist viele Möglichkeiten denkbar, gewisse Daten, Datenauswahlen oder Zusammenhänge zu veranschaulichen. Natürlich sind für eine gegebene Datenauswahl manche Diagrammtypen ungeeignet oder nicht sinnvoll – häufig in Abhängigkeit von Anzahl und Wertebereich der Attribute. Aber auch unter den grundsätzlich geeigneten Darstellungsarten können bestimmte anschaulicher sein, mehr oder weniger gut die intendierte Information transportieren oder ästhetisch ansprechender sein – häufig in Abhängigkeit konkreter Attributwerte und ihrer statistischen Eigenschaften (Minimum- und Maximumwert, Ausreißer, Werteverteilung etc.). Im Extremfall kann eine ungeschickte Visualisierung sogar irreführende Assoziationen bei den Rezipierenden wecken.

Abb. 2: Unterschiedliche Visualisierungen für dieselben Daten

Abb. 3: Diagrammdarstellung im Vergleich
Die Beispiele in dieser Grafik zeigen, dass schon bei sehr einfach strukturierten und kleinen Datenmengen unterschiedliche Darstellungen verschieden leserlich, übersichtlich und verständlich sind. Die Konfiguration des Diagramms wurde durch Detaileinstellungen auf eine Ergebnismenge hin optimiert. Sie funktioniert aber nicht mehr gut für andere Daten. Zielvorstellung ist es, dass sich die Darstellung so wie im unteren Teil der Illustration dynamisch an die aktuellen Daten anpasst.
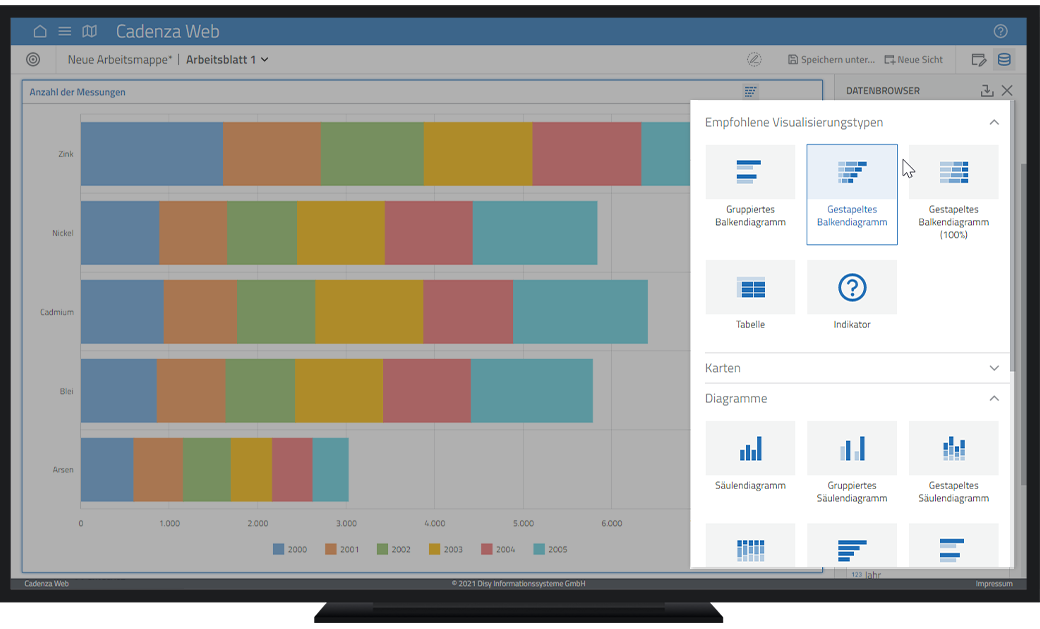
Abb. 4: disy Cadenza macht regelbasierte Vorschläge für Diagrammtypen
Im Idealfall findet man die „beste“ Datenvisualisierung im gegebenen Verwendungskontext also mithilfe von Wissen über die Daten und die Merkmale der verschiedenen Visualisierungsmöglichkeiten, Wissen über das Anwendungsthema und vielleicht sogar Wissen über das Zielpublikum. Mithilfe einfacher Heuristiken (regelhaftes Erfahrungswissen) auf Basis der aktuellen Datencharakteristika macht disy Cadenza schon heute automatisierte Vorschläge für die Visualisierung einer gegebenen Datenauswahl. Dies vereinfacht und beschleunigt die Arbeit der Analysierenden und kann die Ergebnisqualität steigern.
AIDA-Vis will Empfehlungssystem für Datenvisualisierungen entwickeln
Um die Vorschlagsgenerierung für die automatisierte Datenvisualisierung weiter voranzubringen, haben sich Disy und der langjährige Forschungspartner FZI zusammengetan, um das Forschungsprojekt „AI-basiertes interaktives Empfehlungssystem für komplexe Datenvisualisierungen“ (AIDA-Vis) aufzusetzen.

Abb. 5: AIDA-Vis Projektlogo, Kooperationspartner und Fördermittelgeber
In dem Projekt soll untersucht werden, wie man den Nutzenden von disy Cadenza weiterführende, kontext-basierte Empfehlungen bei der Datenanalyse geben kann. Es soll erforscht werden, wie sich das dazu erforderliche Visualisierungswissen während der Benutzung aus der Anwendungsinteraktion automatisiert aufbauen lässt. Diese Aktivitäten werden vom Bundesministerium für Bildung und Forschung (BMBF) im Rahmen der Fördermaßnahme "Erforschung, Entwicklung und Nutzung von Methoden der Künstlichen Intelligenz in KMU (KI4KMU)" unter dem Förderkennzeichen 01IS20097 finanziell unterstützt. AIDA-Vis hat eine Laufzeit von zwei Jahren und ist am 1. Januar 2021 gestartet.
Bestärkendes Lernen als Grundidee
Aufbauend auf den Vorarbeiten des FZI verfolgt AIDA-Vis den folgenden technischen Lösungsansatz: Ziel des Ganzen ist die automatische Erzeugung geeigneter Visualisierungen für eine gegebene Datenmenge. Diese werden vom Visualisierungsgenerator erzeugt, dem Empfehlungssystem im engeren Sinn. Dieses Modul greift auf die darzustellenden Daten und auf relevante Metadaten (Schema, Werteverteilungen, statistische Charakteristika) zu bzw. kann diese aus den Daten ableiten. Der Visualisierungsgenerator nutzt die Operatoren der Visualisierungsbibliothek und kennt auch deren Charakteristika. Für die technische Umsetzung des Visualisierungsgenerators werden im Projekt verschiedene Ansätze erprobt, die man aus der Forschung zu Recommender-Systemen kennt. Diese umfassen sowohl „klassische“ Ansätze mithilfe neuronaler Netze als auch solche auf Basis einer Nutzenfunktion.
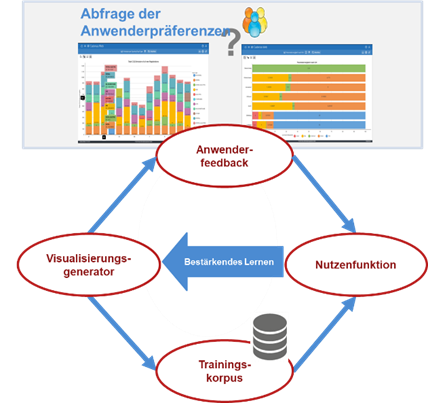
Abb. 6: Technischer Lösungsansatz von AIDA-Vis
Das Visualisierungswissen des Generators soll mithilfe eines Algorithmus zum Bestärkenden Lernen (Reinforcement Learning, RL) aufgebaut und kontinuierlich verbessert werden. Ein solcher RL-Algorithmus benötigt Feedback aus der Umgebung, welche Aktionen sich „gut“ oder „schlecht“ bewähren. Bei der vorliegenden Aufgabenstellung muss dies von den Anwendenden geliefert werden, die vom System präsentierte Visualisierungsvorschläge als besser oder schlechter bewertet. Um die erforderliche Interaktion mit den Nutzenden möglichst ungestört zu gestalten, sollen immer nur zwei Alternativen zur Auswahl gestellt, werden. Die Abfrage der Anwenderpräferenzen ist somit „minimal invasiv“.
Die eigentliche „Intelligenz“ des Lernverfahrens liegt darin, bei der Auswahl der beiden Visualisierungsalternativen solche Varianten zu wählen, die ein schnelles Konvergieren der Lernfunktion ermöglichen. Mithilfe des Lernalgorithmus kann dann in jedem Lernschritt die Nutzenfunktion des RL- und des Recommender-Systems adaptiert werden. Alle Entscheidungen werden im Trainingskorpus gespeichert, der sowohl den Warmstart als auch das inkrementelle Lernen ermöglicht.
Durch die Konsultation der Benutzenden während des Erlernens bei der Verwendung haben wir einen Active-Learning-Ansatz, der sich auch über die Zeit an veränderliche Situationen anpassen kann. Diese Darstellung ist natürlich an verschiedenen Stellen noch etwas vereinfachend. Insbesondere ist zur Durchführung einer komplexen Visualisierungsaufgabe nicht nur eine einzige Entscheidung zu optimieren, sondern von der Datenauswahl über die Datenvorbereitung, die Diagrammauswahl bis zur Diagrammparametrisierung sind verschiedene Arbeitsschritte auszuführen. Dies soll mithilfe von Markov-Entscheidungsprozessen modelliert werden.
Aktueller Stand im Projekt und Ausblick
Aktuell befindet sich das Projektteam mitten in der Implementierung und hofft, früh im Jahr 2022 erste Ergebnisse präsentieren zu können. Die übertragbaren Ergebnisse des FuE-Projekts sollen mit der Fachöffentlichkeit diskutiert und die generischen Lösungsbausteine voraussichtlich auch als Open-Source-Komponenten verfügbar gemacht werden.
Wenn sich die Forschungsergebnisse mittelfristig in die disy Cadenza-Plattform einbauen lassen, stellen sie einen erheblichen Vorteil bei der Realisierung datengetriebener Entscheidungen in der öffentlichen Verwaltung dar, weil Visual Analytics auch bei Disy-Kunden ohne vertiefte IT- und Data-Science-Kenntnisse schneller, einfacher und besser nutzbar gemacht werden kann.
Innerhalb der strategischen Technologieentwicklung bei Disy ordnen sich die AIDA-Vis-Arbeiten in die Zielsetzung ein, disy Cadenza schrittweise zum Werkzeug für Augmented Analytics zu machen. Bei Augmented Analytics geht es darum, auch Fachanwendenden ohne tiefte Technologiekenntnisse mächtige Funktionalitäten zur Datenanalyse anbieten zu können, indem Methoden der Künstlichen Intelligenz, des Maschinellen Lernens und der Sprachverarbeitung für eine teilweise Prozessautomatisierung und einfachere Zugänge zu komplexen Verarbeitungsmethoden genutzt werden.
Wenn Sie sich für den weiteren Projektfortschritt von AIDA-Vis interessieren oder gemeinsam mit Disy spannende Fragen der intelligenten Datenanalyse oder der innovativen Verwaltungsdigitalisierung forschen möchten, treten Sie mit uns in Kontakt.



