Filialnetzoptimierung: Mit disy Cadenza und Location Intelligence den idealen Standort finden
Teil 2 unserer Einzelhandelsanalyse bringt Analyseerweiterungen ins Spiel
Der Raumbezug in Daten liefert oftmals neue Erkenntnisse, die ausschlaggebend für weitreichende Entscheidungen sein können – Stichwort: Location Intelligence. Dabei geht es aber nicht nur um das schlichte „Wo“, also bspw. „Wo befinden sich die Lieferadressen meiner Online-Verkäufe?“, sondern auch um das „Warum“ und das „Wie“: Warum häufen sich Bestellungen in bestimmten Regionen? Welche Faktoren beeinflussen das Kaufverhalten dort? Wie lassen sich diese Muster nutzen, um Lieferketten effizienter zu gestalten oder neue Märkte zu erschließen?
In Teil 1 unserer fiktiven Einzelhandels-Datenstory haben wir mittels Location Intelligence über den Tellerrand von „klassischer“ Business Intelligence hinausgeschaut und dadurch Erkenntnisse erhalten, die bisherige Analysen in einem ganz neuen Licht darstellten.
Teil 2 knüpft direkt daran an und bringt zusätzlich erweiterte statistische Analysen ins Spiel. Basierend auf verschiedenen räumlichen Informationen untersuchen wir, wo eine Erweiterung des Filialnetzes am sinnvollsten ist.
Erste Schritte zur Filialnetzoptimierung

Abb. 1: Filial-Performance-Dashboard
Nachdem wir in Teil 1 identifiziert haben, welche Filialen ganzheitlich gesehen, also mit Einbezug von Online- und Offline-Verkäufen, eine schlechte Performance zeigen, wird nicht nur die Schließung von Filialen, sondern auch die Eröffnung neuer Filialen geplant. Dabei wird nichts dem Zufall überlassen: Für die Filialnetzoptimierung sollen verschiedene Faktoren berücksichtigt werden.
Internen Unternehmensdaten des Kinderkleidungsunternehmens reichen für dieses Vorhaben nicht aus. Zusätzlich werden daher auch externe Daten hinzugezogen. Ergänzend zu den bisher genutzten Stadtteildaten Hamburgs nutzen wir auch demografische Daten, wie z. B. Informationen zur Altersstruktur, zur Bevölkerung, zum Wohnumfeld oder sogar zum durchschnittlichen Nettoeinkommen pro Stadtteil.
Relevante Faktoren identifizieren
Nachdem wir unsere Daten beisammenhaben, lautet die Frage, die wir uns stellen: Welche Standortfaktoren sind für die Filialgeschäfte vorteilhaft? Mögliche Faktoren könnten sein: Einwohnerdichte, Haushalte mit Kindern oder auch mit höherem Durchschnittseinkommen, da es sich um hochpreisige Kleidung handelt.
Um herauszufinden, was starke Standortfaktoren für uns sind, untersuchen wir zuerst bestehende Filialen und deren Umgebung. Dafür sollen die Stadteilstatistiken auf die Filialeinzugsgebiete abgebildet werden. Wir verschneiden also über eine Datenanreicherung jedes Einzugsgebiet mit den dazugehörigen Stadtteildaten. Wenn Sie in der folgenden Karte ein Einzugsgebiet anklicken, sehen Sie in der Objektinformation alle durch die Verschneidung entstandenen Daten.
Mittels Regressionsanalyse Zusammenhänge prüfen

Abb. 2: Dialog zur Regressionsanalyse
Jetzt ist es wichtig, nicht einfach irgendwelche Faktoren als relevant zu beurteilen, sondern genau die Faktoren zu identifizieren, die in Zusammenhang mit dem Umsatz stehen. Dazu eignet sich eine Regressionsanalyse sehr gut. Zwar ist eine solche Regressionsanalyse nicht nativ als Funktion in disy Cadenza verfügbar, aber unsere Datenanalyse-Software kann über die Analyseerweiterungs-API sehr leichtgewichtig um benötigte Berechnungsfunktionen erweitert werden (Abbildung 2). Für die Regressionsanalyse binden wir hier ein einfaches Python-Skript ein, das die Berechnungen im Hintergrund ausführt.
Danach können wir unsere Regressionsanalyse durchführen. Dabei untersuchen wir den statistischen Einfluss der Standortfaktoren „Bevölkerung u15“, „Einkommen“, „Einwohnerdichte“ und „Haushalte mit Kindern“ auf die Zielgröße „Filialumsatz“.

Abb. 3: Ergebnisse der Regressionsanalyse
Die Analyseerweiterung liefert uns das Berechnungs-ergebnis direkt als Objekttyp in disy Cadenza. Es ist damit ready-to-use, sodass wir die neuen Kennzahlen direkt in einer Tabelle betrachten können.
Der Wahrscheinlichkeitswert (p-Wert) bemisst hier die Wahrscheinlichkeit einer zufälligen Korrelation. Je niedriger dieser Wert ist, desto wahrscheinlicher ist also, dass ein Zusammenhang besteht. Bei einem p-Wert von < 0,05 können wir davon ausgehen, dass ein relevanter Zusammenhang besteht.
Die Tabelle (Abbildung 3) liefert uns somit bereits die Erkenntnis: Das Einkommen pro steuerpflichtiger Person zeigt eine Abhängigkeit. Aber nicht allein das ist entscheidend.
Mehr Faktoren für ein besseres Ergebnis
Eine Standortanalyse sollte sich aber nicht nur auf einen Faktor stützen. Für ein bestmögliches Ergebnis sollten noch weitere Faktoren berücksichtigt werden. Deshalb prüfen wir in nachfolgenden Regressionstests noch weitere Datensätze. Und dabei stellen sich tatsächlich noch zwei weitere signifikante Umgebungsvariablen heraus: die Konkurrenzstandorte und der Kaufkraftindex. Diese nehmen wir zu unserer Analyse hinzu.
Als nächstes stellen wir alle drei Faktoren jeweils in einer Karte dar. Je dunkler ein Stadtteil eingefärbt ist, desto höher ist das Einkommen, die Konkurrenzdichte und die Kaufkraft. Bei der Betrachtung dieser drei Karten nebeneinander ist es noch sehr schwer, visuelle Muster zu erkennen. Deshalb möchten wir diese drei Karten kombinieren und alle Informationen für die Bewertung in einem einzigen Karten-Layer zusammenführen.
Dazu führen wir eine gewichtete Gebietsbewertung durch, zu sehen in Abbildung 4. Wie schon bei der vorausgegangenen Regressionsanalyse bedienen wir uns hier an den umfassenden Möglichkeiten der Analyseerweiterungen in disy Cadenza: Wir implementieren in Python eine gewichtete Gebietsbewertung, die wieder über die Analyseerweiterungs-API eingebunden wird. Mit der neu erstellen Analyseerweiterung führen wir dann eine Datenanreicherung an den Stadtteildaten durch.

Abb. 4: Gewichtete Gebietsbewertung
Die drei Attribute müssen dabei gewichtet werden:
- Einkommen pro steuerpflichtiger Person: 1
- Kaufkraftindex: 2
- Konkurrenzgeschäfte: -1
Besonders wichtig ist uns die Kaufkraft. Deshalb wird sie mit „2“ bewertet. Außerdem sollen sich wenige Konkurrenzgeschäfte in der Nähe befinden. Darum gewichten wir diesen Faktor mit „-1“.
Man könnte noch beliebig viele weitere Faktoren mit einbeziehen. In diesem Fall beschränken wir uns aber auf diese drei.
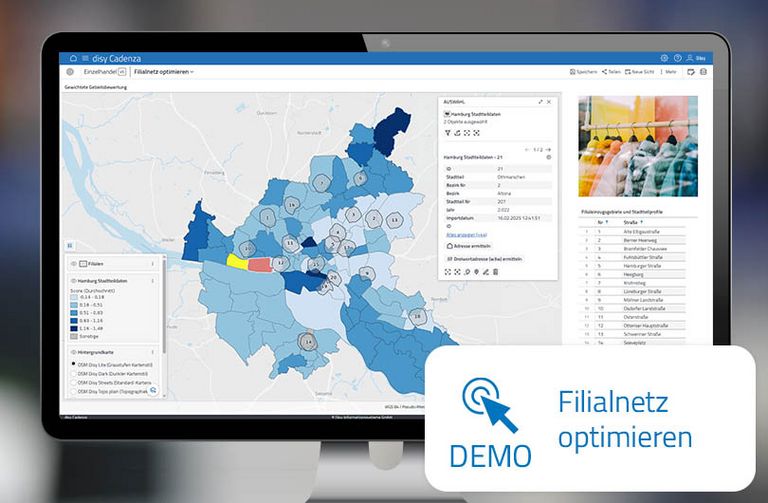
Das Ergebnis dieser Datenanreicherung ist ein neues Attribut, das direkt für die Analyse im Datenmanager bereitsteht. In der Karte aufbereitet sehen wir die für einen neuen Standort am besten geeigneten Stadtteile (Abbildung 5). Je dunkler die Einfärbung, desto besser wurde der Stadtteil bewertet. Vor allem Nienstedten und Othmarschen im Westen, Harvestehude und HafenCity in der Mitte und Wohldorf-Ohlstedt im Norden Hamburgs scheinen besonders gut für die Eröffnung eines neuen Standorts unserer Einzelhandelskette geeignet zu sein.

Abb. 5: Die Ergebniskarte ist eine Kombination aus allen relevanten Faktoren
Und man könnte immer weiter optimieren …
Eine solche gewichtete Gebietsbewertung ist die optimale Methode, wenn viele Faktoren zusammengebracht werden sollen. Dabei ist man nicht auf die Stadtteilebene beschränkt, sondern kann das Ganze auf jeder erdenklichen Ebene durchführen.
Jetzt, da wir die optimalen Stadtteile für einen neuen Standort identifiziert haben, könnte man die Analyse um weitere Aspekte erweitern, indem wir bspw. weiter in die Karte reinzoomen und Fußgängerzonendaten mit einbinden. Auch Zensusdaten, also statistische Daten zur Bevölkerung und Wohnsituation, könnten auf dieser Ebene mit einbezogen werden.
Mit wenigen Schritten zum idealen Standort
Mit den umfassenden Analysemöglichkeiten in disy Cadenza bekommen Sie innerhalb von kurzer Zeit Erkenntnisse geliefert, die Sie weiterbringen.
Unsere Analyse begann in Teil 1 mit einem „klassischen“ Business Intelligence-Dashboard, welches wir dann schrittweise um den Geo-Aspekt erweitert haben. Location Intelligence lautete dabei das Zauberwort, das die neue Perspektive auf die Sachlage eröffnete. Location Intelligence verbindet Kennzahlen mit Raumbezug – und macht dadurch sichtbar, wo Chancen liegen, warum Standorte erfolgreich sind und wie sich Investitionen optimal steu-ern lassen. Mit disy Cadenza werden diese Analysen nahtlos in Dashboards und Reports integriert – für fundierte Entscheidungen mit klarem Standortvorteil.
In Teil 2 haben wir uns an den umfassenden Möglichkeiten der Analyseerweiterung in disy Cadenza bedient, um komplexe Fragestellungen beantworten zu können. Die Übergänge waren dabei fließend – von der reinen Kennzahlenbetrachtung bis hin zu tiefen räumlichen Analysen. Das Ergebnis: bessere Entscheidungsgrundlagen für Filialschließungen und Standorterweiterungen.